搭建自己的Git服务器失败了
本来想自己在自己的服务器上面搭建一个git服务器用来进行版本控制,但是使用ssh的方式搭建的出了好多问题,有些问题查了挺久也没解决,暂时还是先用CSDN的好了,毕设要紧,不能花太多时间在其他东西上面

专注游戏服务器开发

搭建自己的Git服务器失败了
本来想自己在自己的服务器上面搭建一个git服务器用来进行版本控制,但是使用ssh的方式搭建的出了好多问题,有些问题查了挺久也没解决,暂时还是先用CSDN的好了,毕设要紧,不能花太多时间在其他东西上面
放完假,下一步该走了
5.1过去了。
这个假期终于去到了江门的五邑大学,貌似是很久之前就想去那里玩玩。
但是后来总是因为这样那样的事情耽搁了。
有句话说的挺好的。
那就是,想去就要去,你能去只有现在,以后不一定比现在有机会过去。
受到了那边同学的很好的款待。
哈哈哈,好开心的说。
这个五一过得很开心。
下一步也应该开始了。
下一步,数据结构以及算法。
还有那个五子棋的游戏,有空也要开始搞了。
数据库设计联合主键设为外键的问题
很多时候我们在数据库设计中都会遇到这样的问题:
有两个表 ,例如(红色的是主键)
学生(学号,姓名,性别,专业号,班级号)
student(sno,sname,sex,spno,class_no);
专业(专业号,专业名称,上课学时);
department(spno,sname,semester);
班级:(专业号,班级号,班主任);
class(spno,class_no,header);
这个时候,我们想把student表里面的class_no设为外键,references class表,这个时候应该怎么做呢?
我一开始的做法是:
alter table student
add constraint fr_student foreign key(class_no) references class(class_no);
会出现什么问题呢?
消息 1776,级别 16,状态 0,第 1 行
在被引用表 ‘class’ 中没有与外键 ‘fr_student’ 中的引用列列表匹配的主键或候选键。
消息 1750,级别 16,状态 0,第 1 行
无法创建约束。请参阅前面的错误消息。
会报错!
为什么呢?
这个时候我们就好好好理解一下定义了!
什么是外码,外码设置有什么条件?
其中有一点很重要的就是:外码必须是另外一个表的主码!
这里,我们的student表中的class_no如果想要设计成为一个外码,我们首先要找一下,它是哪一个表的主码?
class表?
class表中的主码是(spno,class_no);这个才是class的主码,是联合主键!
所以,如****果你设置联合主键,那么外键必须同时引用两个主键属性,否则只能用check约束来实现参照关系。
所以,一般这个时候你可以回去看看语意有没有理解错误,我的一开始就是因为语意理解错误了,才会出这种情况,我的student表中的(spno,class_no)应该设置成为外键才对。
写的不好的可以告诉我一下,让我修改一下
最近总结了很多C以及Unity的基础知识,分享一下
最近实习过程中总结了很多C#以及Unity的基础知识,分享一下,和新手们一起学习进度。
大神请直接无视,因为我也是这方面的新手~~~
博客前两天访问量突破了20W,虽然有6W是不知道是谁的爬虫爬到了我这里
不知不觉写博客已经一年多了~~
写博客对自己技术的提升是很大的,因为要分享一个东西,必然是自己要非常熟悉,这样自己就会花更多的时间去研究更多更深入的知识,自然也就学的多了~~
实习已经过了两个多月了,最近没那么忙,节奏也稍微慢一点,总结一下之前的一些知识点。
Nice~~~
你的人生永远不会辜负你的。那些转错的弯,那些走错的路,那些流下的泪水,那些滴下的汗水,那些留下的伤痕,全都让你成为独一无二的自己。—— 朱学恒
梦起始的地方
上个世纪80年代的一天,在美国佛蒙特溜冰场的座位席上坐着一个年轻人,他静静地坐着,看着在眼前不时闪过的那些溜冰人,此时溜冰场上空的温暖阳光可以让他很享受着这种美好的时光。自从他卖掉了家传的卷烟纸厂后,得到了一笔可观的资金,他正琢磨着如何借着这笔钱再发一次横财。
在溜冰场旁边有一家咖啡店,每次他到溜冰场的时候,都会在这个咖啡店里喝上一杯。这家店的咖啡很合他的口味,最后他把这家小店买了下来,自己卖咖啡。
一年后,他成立了一家咖啡烘焙公司,但是对于一个只有卷烟纸优势的人来说,想要在咖啡这个陌生的领域有所建树,不仅需要有常人没有的努力,机遇也很重要。因此,一开始的时候,公司并没有赚钱,在最初的3年里反而亏了上百万美元。对于一个商人来说,亏钱是最不愿意看到的事情。为此他很留意顾客的意见,经常免费邀请顾客品尝咖啡,提出意见和建议,并且立马着手改善,但是他的公司生意还是不见起色。
一次偶然的机会,前来他店里喝咖啡的两个附近公司员工的谈话,被他无意间听到了,员工抱怨说公司的速溶咖啡非常难喝,让员工出来喝咖啡,老板又不乐意,很是苦恼,每次都是偷偷溜出来喝。说者无意,听者有心。为什么不把自己美味的咖啡卖到办公室去?他问自己。于是他开始把重心从咖啡店转移到办公室去,他马上找到当时的办公用品供应商史泰博,说服了史泰博和他达成打折协议,他的咖啡如愿以偿进入了史泰博北美的600家办公用品超市,并且进入了超市的邮购目录,通过这个渠道,他输送了超过45万公斤的咖啡。
由于他敏锐的商业眼光,考虑到后面的个人咖啡机市场是一个还未开发的处女地,他率先想到投资生产单杯咖啡机和K杯的克里格公司。
他并不满足,他开始考虑不仅要让自己的咖啡在办公室里可以喝到,最好还是能喝现成的。他果断和美国波兰春公司联手推出一种咖啡机,只要加入咖啡,经过一段时间的加热,就可以喝上热气腾腾的咖啡。事实证明,他的想法是对的,因为大部分的公司都愿意安装这种咖啡机,这样就可以避免员工以“咖啡难喝”为理由,上班时间溜出去喝咖啡。靠着咖啡机,他的咖啡市场开始了更加疯狂的扩张。他的目光开始涉及被星巴克忽略的加油站和STOP/SHOP便利店,他要让喜欢他的咖啡的人在任何地方、任何时间都可以自由享用。
由于进入了批发渠道,咖啡的价格开始大幅度降低。而走加油站和便利店的平民路线,又增加了咖啡品牌的影响力。
随后,他的公司年销售额达到1000万美金,分店开了9家,并且还在纳斯达克全球精选市场成功上市。
在咖啡领域,星巴克的老大地位一直无人可以撼动,但是自从有了他之后,他靠K杯和个人咖啡机捆绑销售模式,销售额已经远超星巴克,作为全球增长速度第二快的企业,他公司的股票价4年来狂飙9倍,星巴克只能屈居第二。这家咖啡公司的名字叫“绿山咖啡”,那位在溜冰场上不溜冰而只是喝咖啡的年轻人,就是绿山咖啡的创始人鲍勃·斯蒂勒。
———————-2013/5/7 18:02
用二叉链表实现二叉查找树(二)
<pre code_snippet_id=”367806” snippet_file_name=”blog_20140528_2_6875764” name=”code” class=”cpp”>/*
二叉查找树的链表实现:
以及三种遍历方式,删除节点;
查找节点;
author:天下无双
Date:2014-5-28
Version:3.0
*/
#include
#include
typedef int T;//树内节点的数据类型
using namespace std;
class BiTree
{
private:
struct BiNode{
T data;
BiNode *lchild,*rchild;
BiNode(T d){
data=d;
lchild=nullptr;
rchild=nullptr;
}
};
BiNode *root;
public:
BiTree(){
//root=root->rchild=root->rchild=nullptr;
root=nullptr;
}
~BiTree(){
}
//使用递归创建二叉树
//以二叉排序树的规则建立
//指针的引用写法(推荐使用)
bool addBiNode(BiNode *&nodeRoot,T d){
if(nodeRoot==nullptr){
BiNode *p=new BiNode(d);
nodeRoot=p;
cout<
return true;
}else if(nodeRoot!=nullptr&&d
//往左子树递归
addBiNode(nodeRoot->lchild,d);
}else if(nodeRoot!=nullptr&&d>(nodeRoot)->data){
//往右子树递归
addBiNode(nodeRoot->rchild,d);
}else{
cout<<”树中已有该数据”<<endl;
return false;
}
}
BiNode *&getRoot(){//返回根指针的引用
return root;
}
BiNode *getPtrToRoot()const{
return root;
}
bool Traverse(const BiNode *b,string type)const{
if(type==”PreOrderTraverse”){
cout<<”\n先序遍历的结果为:”<<endl;
PreOrderTraverse(b);
return true;
}else if(type==”InOrderTraverse”){
cout<<”\n中序遍历的结果为:”<<endl;
InOrderTraverse(b);
return true;
}else if(type==”PostOrderTraverse”){
cout<<”\n后序遍历的结果为:”<<endl;
PostOrderTraverse(b);
return true;
}else{
cout<<”遍历类型无效!”<<endl;
return false;
}
}
//查找二叉树中是否存在该值
bool Search(BiNode *&nodeRoot,T d){
if(nodeRoot==nullptr)
return false;
else{
if(nodeRoot->data==d){
return true;
}else if(nodeRoot->data<d){
return Search(nodeRoot->rchild,d);
}else
return Search(nodeRoot->lchild,d);
}
}
//递归查找确定该节点所在位置
bool DeleteBST(BiNode *&nodeRoot,T d){
if(nullptr==nodeRoot)//当该节点为空
return false;
else{
if(nodeRoot->data==d){//
return Delete(nodeRoot);
//Delete(nodeRoot);
}else if(nodeRoot->data<d){
return DeleteBST(nodeRoot->rchild,d);
//DeleteBST(nodeRoot->rchild,d);
}else
return DeleteBST(nodeRoot->lchild,d);
//DeleteBST(nodeRoot->lchild,d);
}
}
protected:
//删除操作
//删除相应节点
//如果该节点是叶子节点,即该节点左右孩子均为空,则只需将父节点指向该节点
//指针置空即可
//如果仅有左孩子或者仅有右孩子,则将对应节点上移
//nodeRoot为要删除的节点
//若既有左孩子,又有右孩子,看下面的注释
bool Delete(BiNode *&nodeRoot){
//如果要删除的节点右子树为空,则只需移动左子树
if(nullptr==nodeRoot->rchild){
BiNode *temp=nodeRoot;
nodeRoot=nodeRoot->lchild;
delete temp;
return true;
}else if(nullptr==nodeRoot->lchild){//若左子树空则移动右子树
BiNode *temp=nodeRoot;
nodeRoot=nodeRoot->rchild;
delete temp;
return true;
}else{//左右子树均非空
//将该节点的左子树的最右边的右节点数据和该节点互换
//或者是将该节点右子树最左端的左节点和该节点数据互换
//我这里是选择左子树的最右节点
BiNode *temp=nodeRoot->lchild;//temp为该节点左子树的根节点
BiNode *preTemp=nodeRoot->lchild;
while(nullptr!=temp->rchild){
preTemp=temp;//令preTemp指向最右节点的前驱
temp=temp->rchild;//一直寻找最右的右节点
//temp指向待删除的节点
}
//这时候temp指向最右的一个节点
nodeRoot->data=temp->data;//交换数据,由于二叉查找树的特性,交换后依旧保持该特性。
/*
50
3070
20
倘若删除的是50,则preTemp=temp=&30
*/
if(temp!=preTemp)
preTemp->rchild=temp->lchild;//令前驱节点的右孩子变成被删除节点的左孩子
else
nodeRoot->lchild=temp->lchild;
delete temp;//删除右节点
return true;
}
return false;
}
//T如果是结构或者类类型,需重载<<运算符
void Visit(const BiNode *r)const{
cout<
}
//利用递归遍历,三种遍历原理都是一样的
//前序遍历,先根遍历
void PreOrderTraverse(const BiNode *nodeRoot)const{
if(nodeRoot!=nullptr)
Visit(nodeRoot);
if(nodeRoot->lchild!=nullptr)
PreOrderTraverse(nodeRoot->lchild);
if(nodeRoot->rchild!=nullptr)
PreOrderTraverse(nodeRoot->rchild);
}
//中根遍历
void InOrderTraverse(const BiNode *nodeRoot)const{
if(nodeRoot->lchild!=nullptr)
InOrderTraverse(nodeRoot->lchild);
if(nodeRoot!=nullptr)//当该点左子树空时
Visit(nodeRoot);
if(nodeRoot->rchild!=nullptr)
InOrderTraverse(nodeRoot->rchild);
}
//后序遍历
void PostOrderTraverse(const BiNode *nodeRoot)const{
if(nodeRoot->lchild!=nullptr)
PostOrderTraverse(nodeRoot->lchild);
if(nodeRoot->rchild!=nullptr)
PostOrderTraverse(nodeRoot->rchild);
if(nodeRoot!=nullptr)
Visit(nodeRoot);
}
};
感觉对于递归中的return还是有点不太清晰。
什么时候该用,什么时候不该用也不太清晰。
测试代码
#include "bit4.cpp"
int main()
{
BiTree b;
//b.addBiNode(&b.root,50);//设立根节点值//二级指针写法
b.addBiNode(b.getRoot(),50);//指针的引用写法
int i;
int arr\[9\]={30,40,35,27,100,90,110,95,-999};
for(int j=0;j<9;j++)
{
i=arr\[j\];
if(i==-999)
break;
b.addBiNode(b.getRoot(),i);
}
b.Traverse(b.getPtrToRoot(),"PreOrderTraverse");
b.Traverse(b.getPtrToRoot(),"InOrderTraverse");
b.Traverse(b.getPtrToRoot(),"PostOrderTraverse");
while(true)
{
int k;
cout<<"\\n输入要查找的值:"<>k;
if(b.Search(b.getRoot(),k))
cout<<"OK"<
用递归实现求一个迷宫是否有通路
今天终于把昨天下午没写出来的迷宫求是否有通路的cpp写出来了
使用递归实现的,不过算法的质量不怎么样,使用穷举法实现的。
在网上搜了一下,发现还有很多的更优的算法,哈哈,不过怎么说都是自己一个个地代码敲出来的。
特点是发现在linux下面调试真的有时候自己会崩溃,还好最终还是搞出来了。
哈哈,发上来给类似我这种的算法新手来一起分享一下;
路径就记录在栈里面,需要得出具体路径的可以小改一下就行了。
findRoad.cpp
//迷宫求解问题思路
//1.用一个矩阵来表示迷宫,即n*m数组
//用穷举法实现;即从入口出发,顺着某一个方向向前探索,若能走通,则继续往前走;
//若到了某一点走不通,则标记该点为不可达
//否则原路返回,换一个方向再继续探索
//具体的请看算法解释
#include
using namespace std;
#include “stack.cpp”
struct box{
bool status;//用于判断该处是否可通
int direct;//用于标记在这里向哪个方向探索过了,
//1234分别代表向左上右下的顺序探索,即顺时针方向
};
struct posType//用于记录某一点的坐标值
{
int x;
int y;
};
bool isEqueal(posType a,posType b)//跟arriived一样,不过名字变了而已
{
if(a.x==b.x&&a.y==b.y)
return true;
return false;
}
bool arrived(posType start,posType end)//判断是否已经到达出口
{
if(start.x==end.x&&start.y==end.y)
return true;
return false;
};
static mStack
const int MAXLINE=5;//需要的时候再改
const int MAXROW=5;
bool findRoad(box (*arr)[MAXROW],posType start,posType end)//注意二维数组的指针表示
{
int x=start.x;
int y=start.y;
if(arrived(start,end))//如果到达
return true;
//还会有下面这种情况
//应该这样表达才对arr+start.x*MAXROW+start.y)->status
//而不是(*arr+i)+j
if((*arr+x*MAXROW+y)->status==false)//假设仅剩该点且该点四周都不可达,则路到了尽头!!
return false;
posType temp;
if(ms.isEmpty())//如果栈空
ms.Push(start);//将当前位置入栈
else //判断是否是上一个点,避免重复入栈
{
ms.GetTop(temp);
if(!isEqueal(temp,start))
ms.Push(start);
}
switch((*arr+x*MAXROW+y)->direct)//检测往哪个方向走过了
{
//derect=0代表未向任何方向探索过,应向左探索
//=1代表要向上探索
case 0:if(y-1>-1&&(*arr+x*MAXROW+y-1)->status)//向左方探索,如果没有越界并且左方是可达的
{
//posType newStart(x-1,y);//以左方作为新起点
posType newStart;
newStart.x=x;
newStart.y=y-1;
(*arr+x*MAXROW+y)->direct=1;//应该是该点=1;该点探索过了而不是下一点
//arr[newStart.x][newStart.y].direct=1;//探索的方向+1
findRoad(arr,newStart,end);//以新起点开始探索
}
else//倘若数组越界了,或者左方不可达,则向上探索
{
(*arr+x*MAXROW+y)->direct=1;//令其=1,再递归调用
findRoad(arr,start,end);//起点不变
};break;
case 1:if(x-1>-1&&(*arr+(x-1)*MAXROW+y)->status)//向上方探索,如果没有越界并且上方是可达的
{
//posType newStart(x,y-1);//以该起点作为新点
posType newStart;
newStart.x=x-1;
newStart.y=y;
(*arr+x*MAXROW+y)->direct=2;//应该是该点=1;该点探索过了而不是下一点
//arr[newStart.x][newStart.y].direct=2;//探索的方向=2
findRoad(arr,newStart,end);//以新起点开始探索
}
else//倘若数组越界了,则向上探索
{
(*arr+x*MAXROW+y)->direct=2;//令其=2,再递归调用,即指示其向下一个方向探索
findRoad(arr,start,end);//起点不变
};break;
case 2:if(y+1<MAXROW&&(*arr+x*MAXROW+y+1)->status)//向右方探索,如果没有越界并且右方是可达的
{
//posType newStart(x+1,y);//以该起点作为新点
posType newStart;
//newStart.x=x+1;
newStart.x=x;//向右应该是y+1
newStart.y=y+1;
(*arr+x*MAXROW+y)->direct=3;
//arr[newStart.x][newStart.y].direct=3;//探索的方向=3
findRoad(arr,newStart,end);//以新起点开始探索
}
else//倘若数组越界了或者不可达,则向下探索
{
(*arr+x*MAXROW+y)->direct=3;//令其=3,再递归调用,即指示其向下一个方向探索
findRoad(arr,start,end);//起点不变
};break;
case 3:if(x+1<MAXLINE&&(*arr+(x+1)*MAXROW+y)->status)//向下方探索,如果没有越界并且下方是可达的
{
//posType newStart(x,y+1);//以该起点作为新点
posType newStart;
newStart.x=x+1;
newStart.y=y;
(*arr+x*MAXROW+y)->direct=4;
//arr[newStart.x][newStart.y].direct=4;//探索的方向=3
findRoad(arr,newStart,end);//以新起点开始探索
}
else//倘若数组越界了或者不可达,更改此点为不可达
{
(*arr+x*MAXROW+y)->direct=4;//令其=3,再递归调用,即指示其向下一个方向探索
findRoad(arr,start,end);//起点不变
};break;
case 4:(*arr+x*MAXROW+y)->status=false;//当四个方向都探索完了之后,均没有通路时,标记该点为不可达状态
posType t;//将当前点出栈
ms.Pop(t);//
if(ms.isEmpty())//如果此时栈已经空了,说明没有路可以回头了,路不通
return false;
ms.Pop(start);//令上一路径为起点,递归找路
findRoad(arr,start,end);
break;
};
};
stack.cpp
//用于实现栈的操作
#include
using namespace std;
//const int MAX=100;//栈最大长度值为100,用数组实现栈
//写成模板类是为了方便我以后使用
template
class mStack{
private:
enum {MAX=1000};
T arr[MAX];
int Size;
int top;//用于指示栈顶位置
public:
mStack()//构建空栈
{
top=-1;//下标为-1则为空栈
Size=0;
}
bool isEmpty()
{
return top==-1;
}
bool isFull()
{
return top==MAX-1;
}
bool Push(T &item)
{
if(isFull())
{
cout<<”stack is full!”<<endl;
return false;
}
//++top;
//arr[++top]=item;
arr[++top]=item;//因为下标从-1开始,使用前+1
//cout<<”this “<<top<<” item push values is :”<<arr[top]<<endl;
Size++;
return true;
}
bool Pop(T &item)
{
if(isEmpty())
{
cout<<”stack is empty!”<<endl;
return false;
}
item=arr[top–];//因为下标从-1开始,top指向当前最后一个元素,使用后-1
//cout<<”this “<<top<<” item pop values is :”<<arr[top]<<endl;
Size–;
return true;
}
bool GetTop(T &item)
{
if(!isEmpty())
{
item=arr[top];
return true;
}
return false;
}
int size()
{
return Size;
}
};
test.cpp
#include
#include
#include
#include “all.cpp”
const int MAXL=5;
const int MAXR=5;
int main()
{
ofstream fout;//(“test1.txt”);//,ios_base::app);//,ios_base::app);
fout.open(“test1.txt”,ios_base::app);
if(!fout.is_open())
cerr<<”open failer!”<<endl;
//box (*b)[MAXR];
box (*b)[MAXR]=new box[MAXL][MAXR];
ifstream fin(“tx.txt”);//从文件中读取迷宫
if(!fin.is_open())
cerr<<”fin open failure!”<<endl;
for(int i=0;i<MAXLINE;i++)
{
for(int j=0;j<MAXROW;j++)
{
int num;
fin>>num;
//*(*(b+i)+j)=new box;
if(num==1)
(*(b+i)+j)->status=false;//给迷宫里的box赋值
//(*(ar+i)+j)->status=false;
else
(*(b+i)+j)->status=true;
(*(b+i)+j)->direct=0;
}
}
fin.close();
posType start;
start.x=0;
start.y=1;
posType end;
end.x=0;
end.y=3;
(*(b+start.x)+(start.y))->status=true;
(*(b+end.x)+end.y)->status=true;
for(int i=0;i<MAXLINE;i++)
{
for(int j=0;j<MAXROW;j++)
{
if((*(b+i)+j)->status)
fout<<”0 “;
else
fout<<”1 “;
}
fout<<endl;
}
fout<<endl<<endl;
fout.close();
if(findRoad(b,start,end))
cout<<”has load!”<<endl;
else
cout<<”no load “<<endl;
}
tx.txt
//可以自己设置迷宫路径和出发点以及出口
1 0 1 0 1
0 0 1 0 0
0 0 1 0 0
0 0 1 0 1
1 0 0 0 0
程序员日记(一)程序员不是个轻松的职业
程序员不是一个轻松的职业,从来都不是。
虽然有时候在其他人看来,这是一份很轻松的工作。
就是在那里敲敲键盘,一个月工资就可以很高。
可是我们背后付出的努力呢?
有谁看到了,为了一个小BUG搞一天是很正常的事情,要是有时候有项目要做,加班一个月也不是不可能的事情。
只可惜我还只是半个程序员,这是一条很长的路,我会慢慢走下去。
-–end
笔试面试2用C实现C库的strcpy函数
其实这也是一个简单的问题,当时我考虑太多了,居然还考虑如果不能完全装进去要不要申请新的空间。
后来后头才发现…
原型声明:extern char *strcpy(char* dest, const char *src);
头文件:#include <string.h> 和 #include <stdio.h>
功能:把从src地址开始且含有NULL结束符的字符串复制到以dest开始的地址空间
说明:src和dest所指内存区域不可以重叠且dest必须有足够的空间来容纳src的字符串。
返回指向dest的指针。
这个函数的前提就是已经有足够的空间来容纳后面的一个字符串。原来是我有点混淆了C的strcpy和strcat !!
对C真心不是太熟,习惯了C++,都快把C给忘了…
这个的实现很简单,但是有很多的细节需要注意。
#include <stdlib.h>
#include <stdio.h>
#include <assert.h> //for assert
char *strcpy(char *str,const char *str2){
assert(str!=NULL&&str2!=NULL);//判断两者是否有一个为空
char *result=str;
while((*str++=*str2++)!=’\0’) ;//一次将字符copy到str
return result;
}
int main()
{
char str[50]=”hello ,c,I love you”;
char str2[50]=”hello,c!but I love c++ more !!”;
printf(“str is %s\n”,str);
printf(“str2 is %s\n”,str2);
strcpy(str,str2);
printf(“after strcpy(str,str2):str=”);
printf(“%s\n”,str);
getch();
getch();
}
首先要检测两个指针的有效性,然后就是在while里面判断循环的终止条件,最后的话看需要是否需要返回值。
上面的是不考虑内存重叠的这种情况。如果内存重叠,建议使用一个网友的做法。
地址:http://blog.csdn.net/gpengtao/article/details/7464061/
strcpy的正确实现应为:
[cpp] view plaincopy
memcpy函数实现时考虑到了内存重叠的情况,可以完成指定大小的内存拷贝,它的实现方式建议查看文章“卓越的教练是如何训练高手的?”,会获益良多,这里仅粘帖函数memcpy函数的实现:
[cpp] view plaincopy
两者结合才是strcpy函数的真正实现吧。
——————————————————————————————————————————————————————————————————
//写的错误或者不好的地方请多多指导,可以在下面留言或者点击左上方邮件地址给我发邮件,指出我的错误以及不足,以便我修改,更好的分享给大家,谢谢。
转载请注明出处:http://blog.csdn.net/qq844352155
author:天下无双
Email:coderguang@gmail.com
2014-10-31
于GDUT
——————————————————————————————————————————————————————————————————
笔试面试3将一个数分解成质因数的形式以及如何判断一个数是否是质数
虽说已经找到了实习,offer也拿了,但是还是决定多上来刷刷一些简单的,很水的笔试面试题。
这些题仅适合学渣级的算法菜鸟学习,ACM的大神们请自动略过。
将一个数分解成质因数的形式,例如:
10=2*5 100=2*2*5*5
其实这道题的实现很简单。设一个i初始值为2,然后用该数一直除,递增i即可。
以下是实现:
#include <stdio.h>
#include <conio.h>
int main()
{
while(true){
printf(“\n请输入数字:\n”);
int number;
scanf(“%d”,&number);
if(number<0){//考虑输入不合法
printf(“输入不合法(<0)”);
continue;
}
if(number==0number==1){//考虑输入的是0或者1
printf(“%d=%d”,number,number);
continue;
}
int i=2;
printf(“%d=”,number);
while(number>=i){
while(number%i==0){ //一直除i,直到不能整除时,i+1
printf(“%d”,i);
if(number!=i)
printf(“*“);
number=number/i;
}
i++;
}
}
getch();
}
测试图:
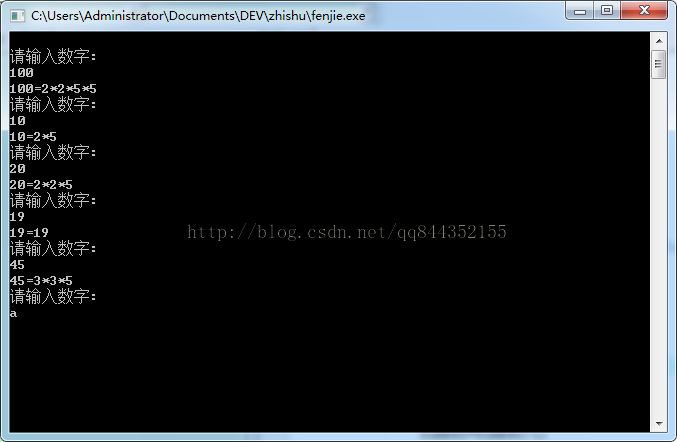
如何判断一个数是否是质数。
这个就更简单了。
直接上源码:
#include <stdio.h>
#include <conio.h>
#define TRUE 1
#define FALSE -1
int isPrime(int number){//c 没有bool类型…
if(number<=1){//考虑输入不合法
printf(“输入不合法(<2)\n”);
return FALSE;
}
if(number==2)
return TRUE;
int i=2;
while(i<=number){
while(number%i==0){
if(i==number)
return TRUE;
else
return FALSE;
}
i++;
}
}
int main()
{
while(TRUE){
printf(“\n请输入数字:\n”);
int number;
scanf(“%d”,&number);
if(isPrime(number)==TRUE)
printf(“%d is a prime number!\n”,number);
else
printf(“%d not a prime number!\n”,number);
}
getch();
}
测试截图:
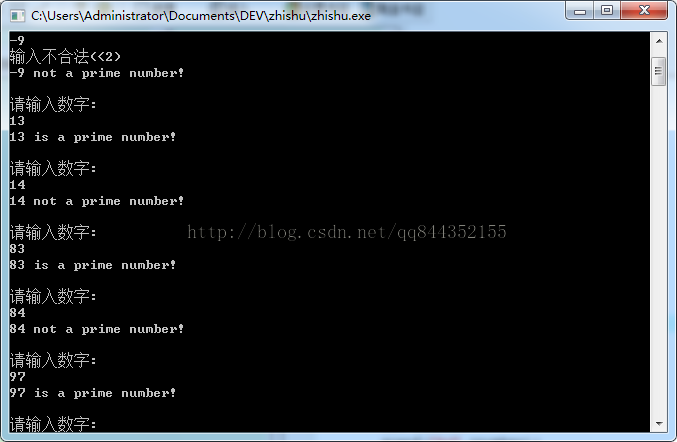
不过如果一个数比较大的时候,这个时间复杂度就会比较大,一个比较好的方法就是利用其平方根。
i的最大值只需递增到sqrt(n)即可。(原因是i*i==n时,i就是中间的那个因子)
源码:
#include <stdio.h>
#include <conio.h>
#include <math.h>
#define TRUE 1
#define FALSE -1
int isPrime(int number){//c 没有bool类型…
if(number<=1){//考虑输入不合法
printf(“输入不合法(<2)\n”);
return FALSE;
}
if(number==2)
return TRUE;
int i=2;
int counts=1;
while(i<=sqrt(number)){
if(number%i==0)//如果整除,因子数+1
counts++;
i++;
}
if(counts==1)
return TRUE;
else
return FALSE;
}
int main()
{
while(TRUE){
printf(“\n请输入数字:\n”);
int number;
scanf(“%d”,&number);
if(isPrime(number)==TRUE)
printf(“%d is a prime number!\n”,number);
else
printf(“%d not a prime number!\n”,number);
}
getch();
}
测试图:
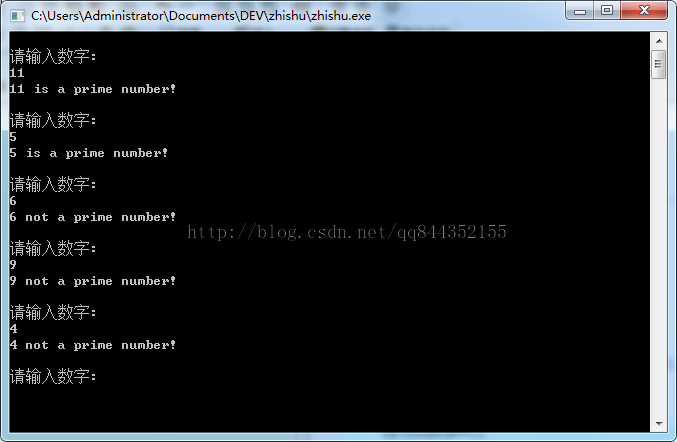
——————————————————————————————————————————————————————————————————
//写的错误或者不好的地方请多多指导,可以在下面留言或者点击左上方邮件地址给我发邮件,指出我的错误以及不足,以便我修改,更好的分享给大家,谢谢。
转载请注明出处:http://blog.csdn.net/qq844352155
author:天下无双
Email:coderguang@gmail.com
2014-11-5
于GDUT
——————————————————————————————————————————————————————————————————
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true